H200 Performance Gains: How Modern Accelerators Deliver 110X in HPC
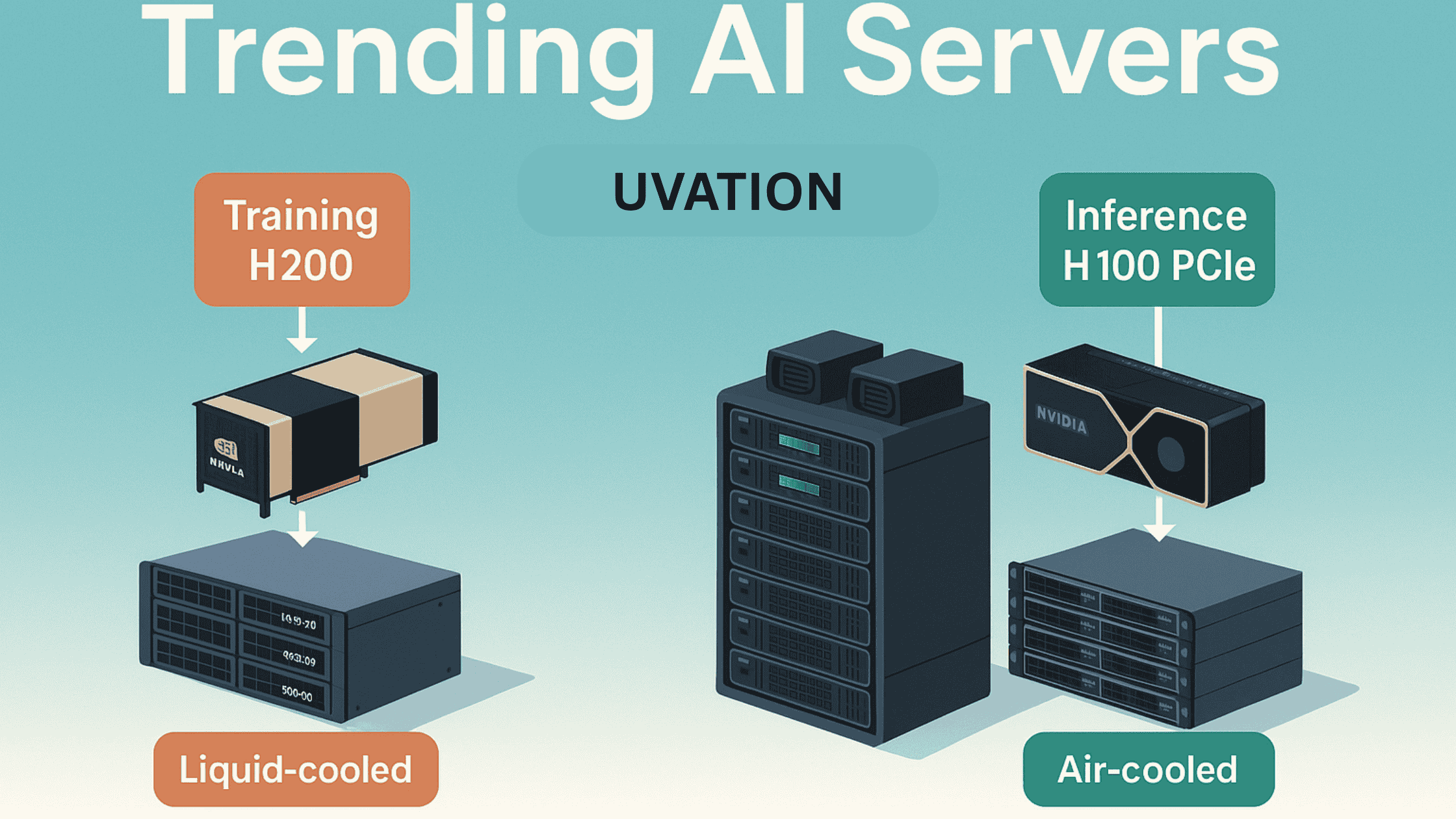
The NVIDIA H200 GPU marks a significant leap in high-performance computing (HPC) and AI inference. Featuring 141GB of HBM3e memory and 4.8 TB/s bandwidth, it surpasses the H100 and A100, solving memory bottlenecks common in large language models and scientific simulations. Equipped with NVLink fabric and Gen 2 Transformer Engines, the H200 enables 110X faster performance in real-world applications like genomics, climate modeling, and computational fluid dynamics. Compared to legacy A100 clusters, H200 clusters deliver significantly reduced latency and higher token throughput, lowering cost per user and improving total cost of ownership (TCO). Uvation benchmarks show the H200 achieving up to 11,819 tokens per second in LLaMA 13B inference workloads. For enterprises seeking efficient HPC acceleration, the H200 offers a scalable, memory-optimized solution with turnkey deployment options, helping organizations reduce infrastructure costs while maximizing AI and scientific computing performance.
4 minute read
•Artificial Intelligence